Projects
StreamTensor: Make Tensors Stream in Dataflow Accelerators
Jan 2024 - May 2025
Document
-
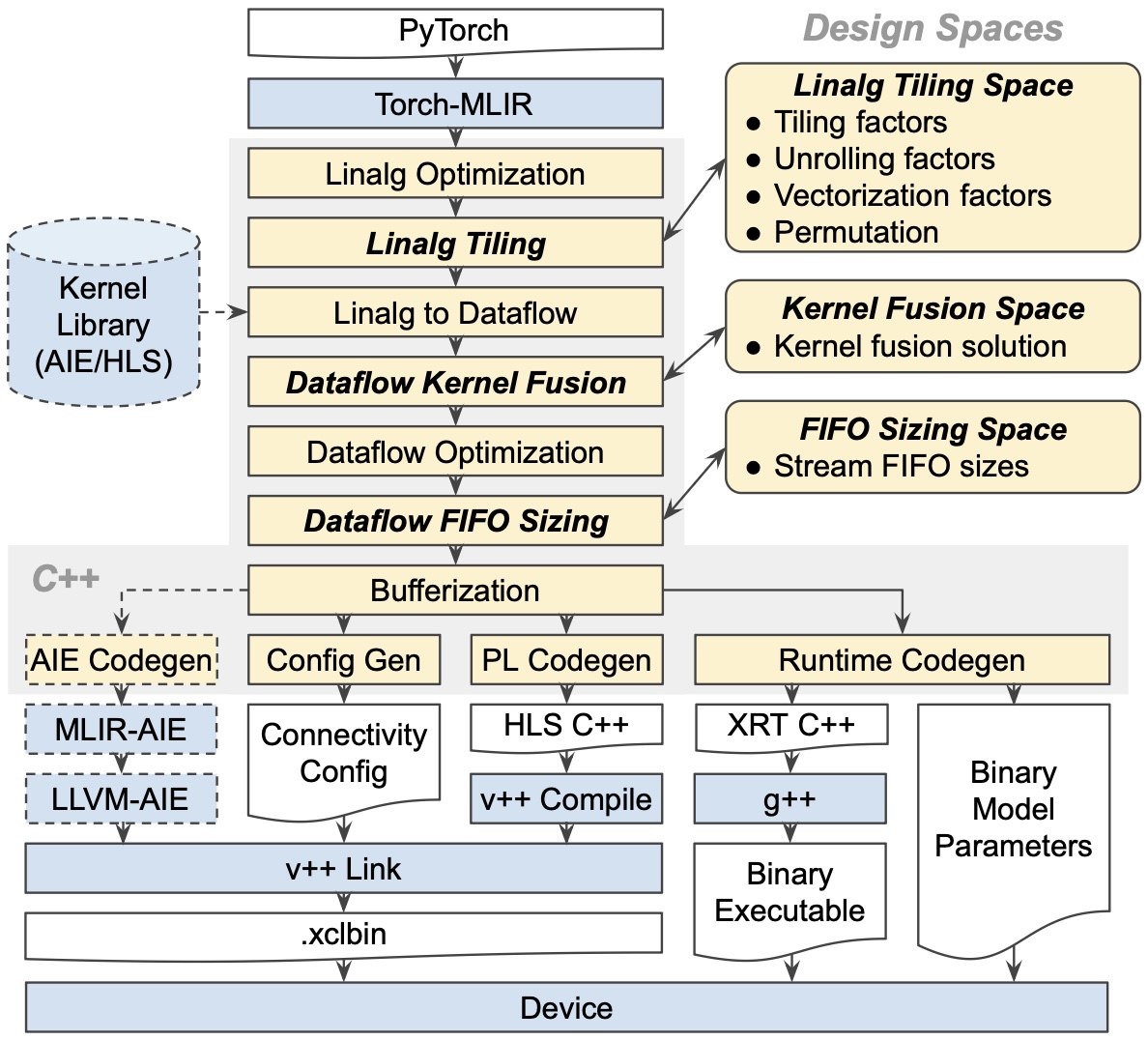
Designed a dataflow-centric typing system and intermediate representation (IR) to model the kernel processing and communication at tensor level in MLIR.
-
Introduced stream-based kernel fusion, on-the-fly stream layout conversion, and dataflow FIFO optimization to reduce off-chip memory access and on-chip memory size.
-
Designed a compilation pipeline that compiles PyTorch model, e.g., large language model (LLM), to low-level IRs targeting dataflow accelerators, such as AMD Versal ACAP and FPGA.
XLS: Accelerated HW Synthesis
May 2023 - Aug 2023
Document / GitHub
-
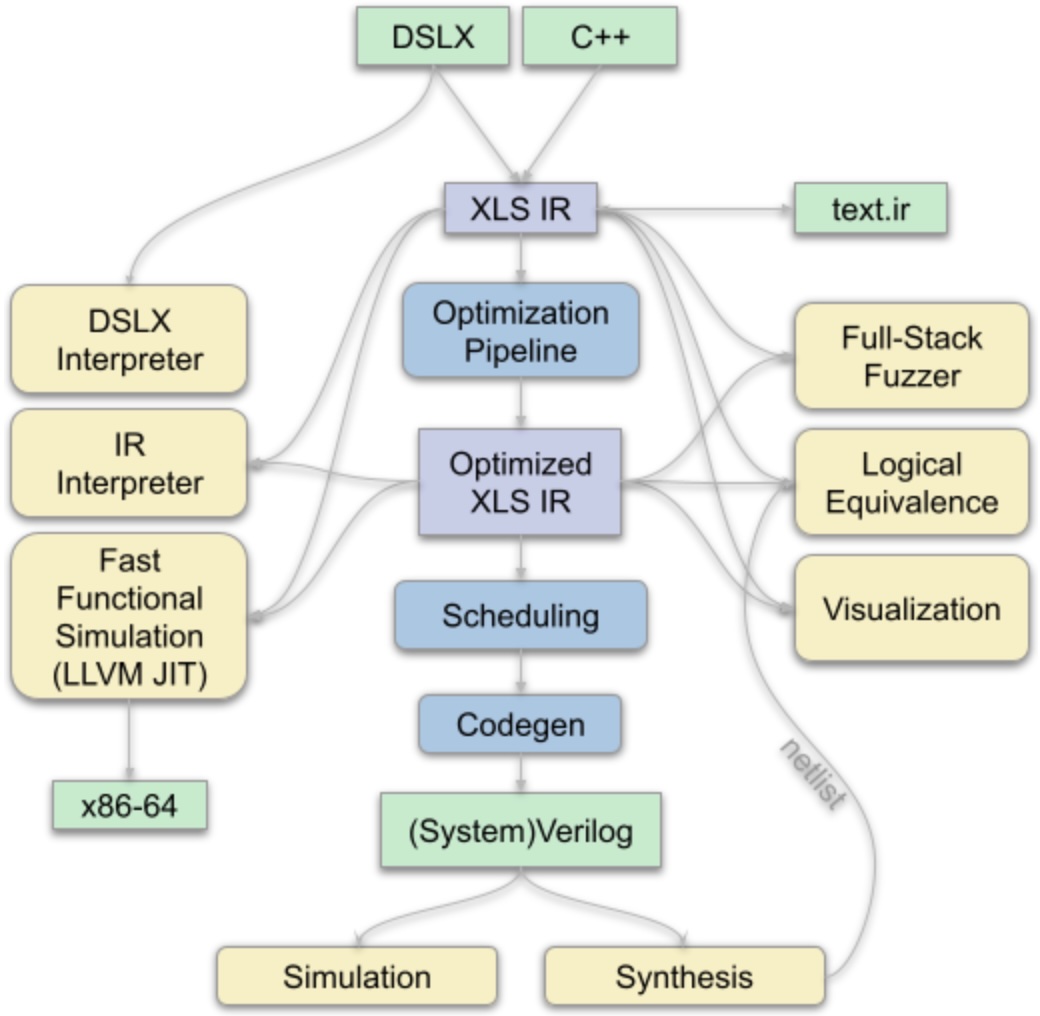
XLS implements a High-level Synthesis (HLS) toolchain which produces synthesizable designs (Verilog and SystemVerilog) from flexible, high-level descriptions of functionality.
-
Proposed a feedback-directed optimization (FDO) method named ISDC that takes downstream tools, e.g., OpenROAD, results as feedback to improve SDC scheduling quality of HLS.
-
Achieved a 28.5% lower register usage compared to the original SDC scheduling on SKY130.
HIDA: A Hierarchical Dataflow Compiler for High-level Synthesis
Mar 2022 - Jan 2024
GitHub
-
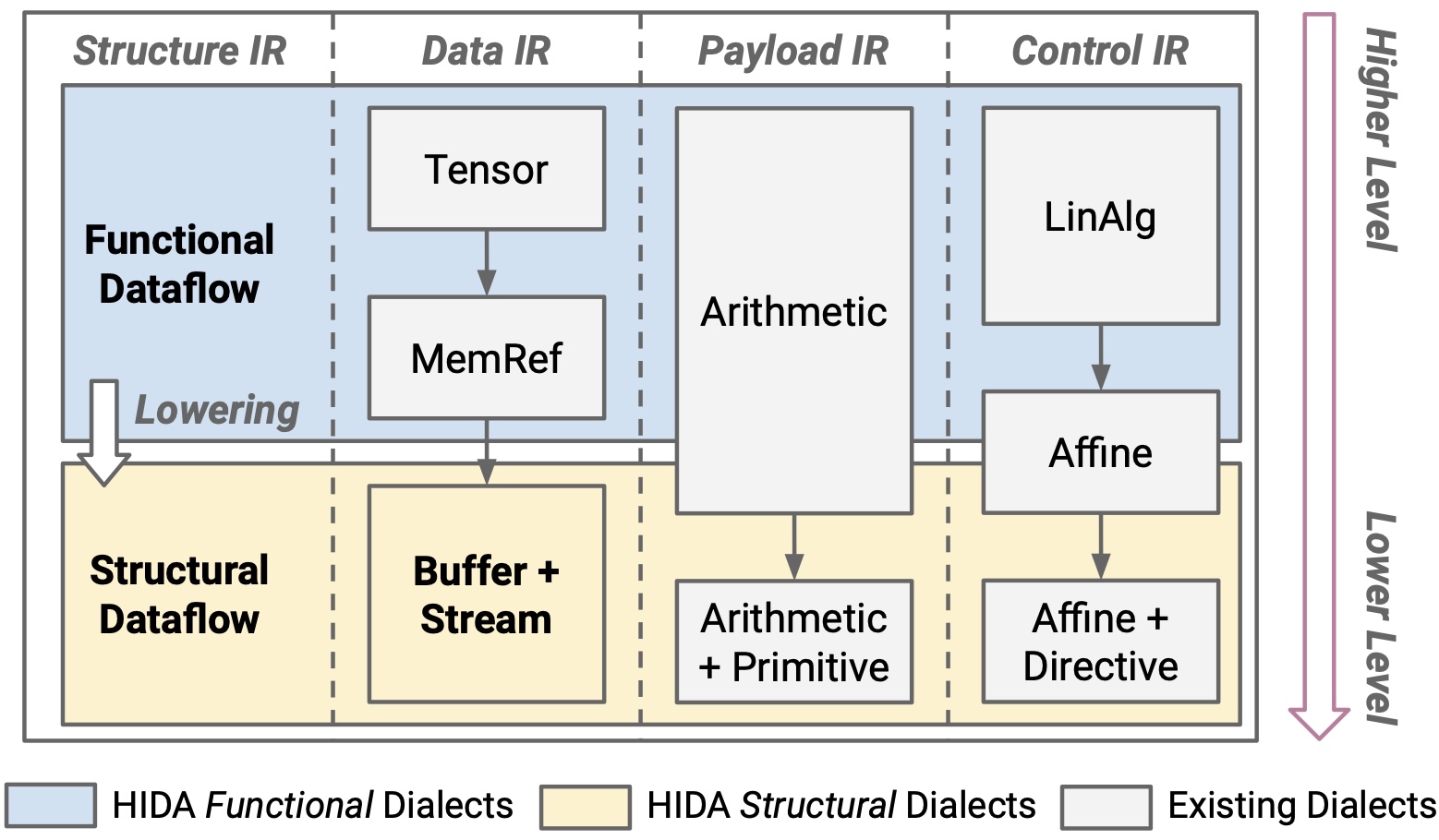
Proposed a hierarchical dataflow intermediate representation (IR) to model and optimize the complicated dataflow structures in High-level Synthesis (HLS).
-
Designed an algorithm to guide the local design space exploration of each dataflow node while keeping the global dataflow balanced and efficient.
CHARM: A Heterogeneous GEMM Accelerator on Versal ACAP
Oct 2021 - Oct 2022
CHARM GitHub / PolyAIE GitHub
-
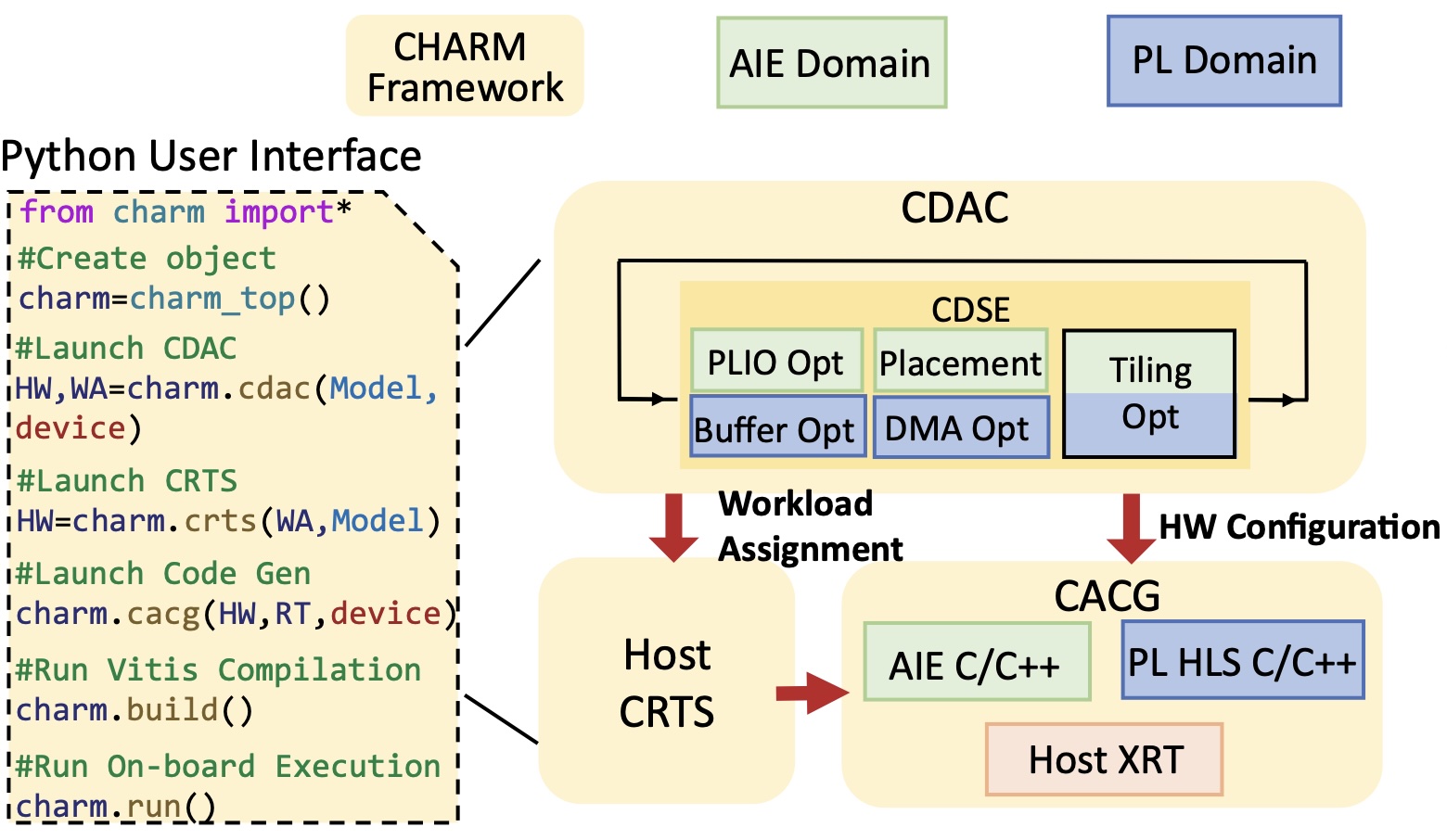
Designed a compilation flow from C/C++ programs to the AI-Engine (AIE) array on AMD Versal ACAP using Polyhedral compilation techniques in MLIR.
-
Mapped GEMM-based models, e.g., BERT and ViT, to accelerators on AMD Versal ACAP; Non-GEMM kernels and data movement kernels are implemented on Programming Logic (PL).
-
Proposed a design space exploration algorithm to determine the tiling strategy at each level of memory.
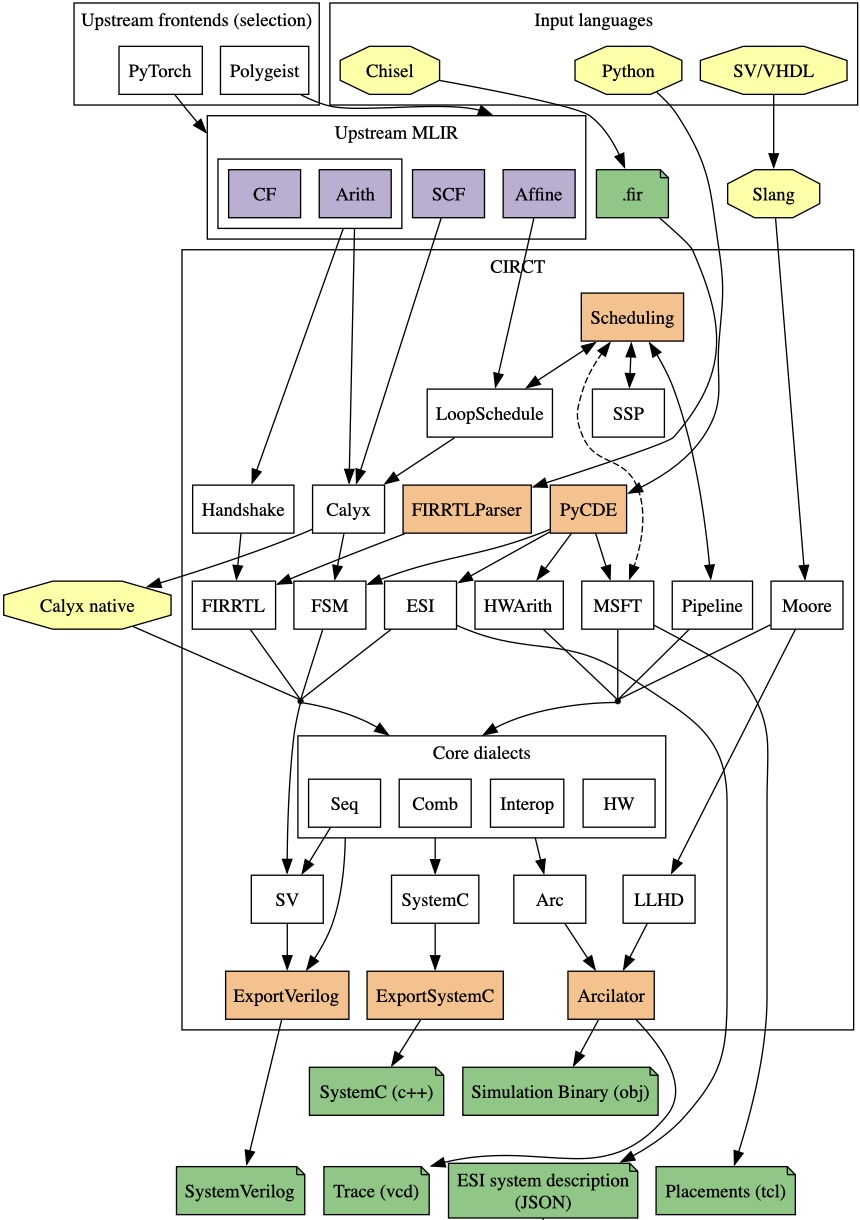
CIRCT: Circuit IR Compilers and Tools
Jun 2020 - Oct 2021
Document / GitHub
-
The CIRCT open-source project is an effort looking to apply MLIR and the LLVM development methodology to the domain of hardware design tools.
-
Contributed to the FIRRTL, HW (Hardware), and SV (SystemVerilog) dialects and transformations to establish the hardware 'core IR' of CIRCT and enable a Chisel to SystemVerilog compilation flow.
-
Contributed a new FSM dialect to represent, optimize, and generate codes for finite-state machines.
-
Contributed to the Handshake and Pipeline dialects to enable a High-level Synthesis (HLS) flow that compiles the 'core IR' of MLIR to the hardware 'core IR' of CIRCT.
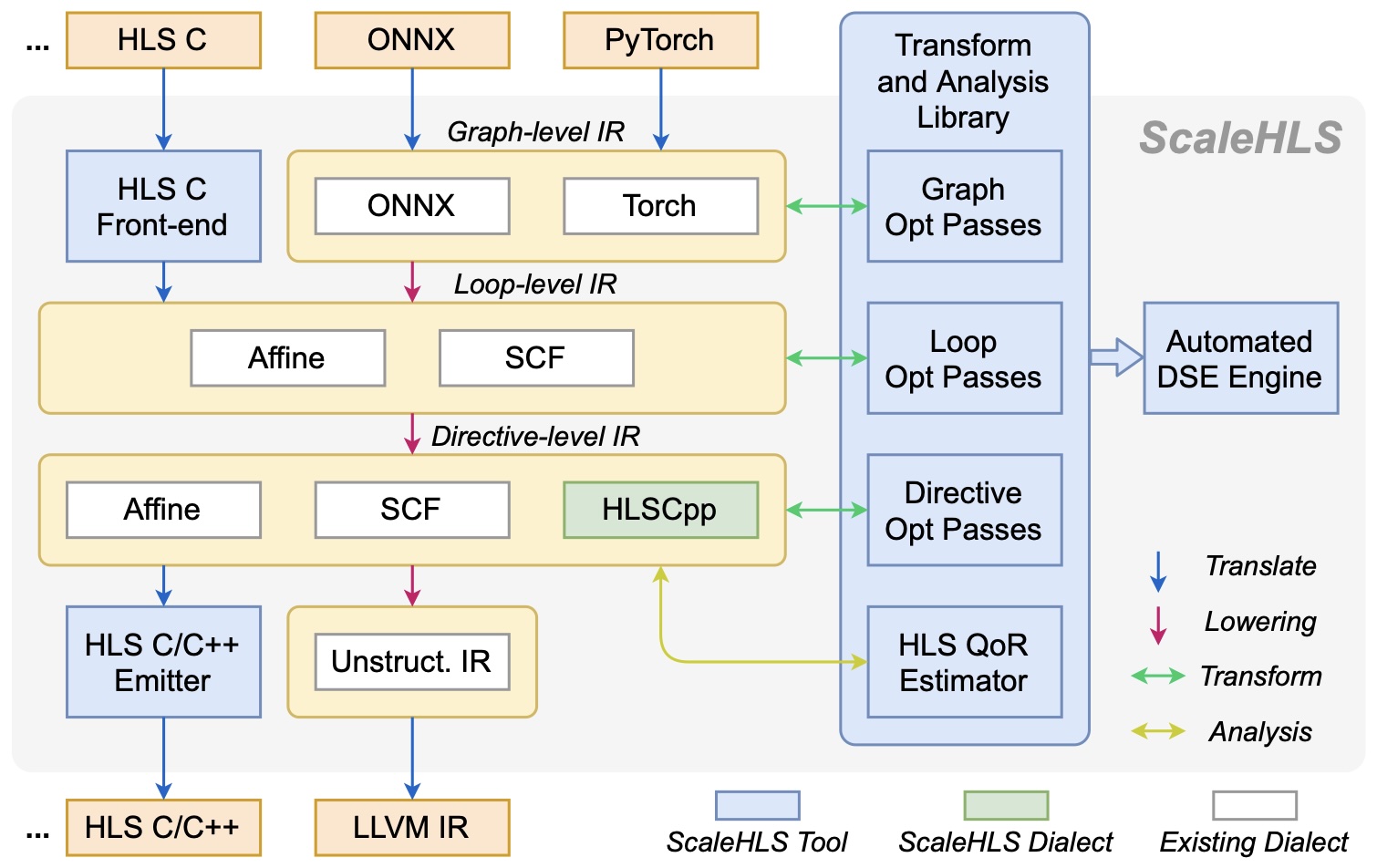
ScaleHLS: A Scalable High-level Synthesis Framework on MLIR
Apr 2020 - Mar 2022
GitHub
-
Designed a multi-level HLS representation and optimization framework in MLIR.
-
Designed an HLS-specific transform and analysis library, including loop and pragma optimizations, an HLS Quality-of-Result (QoR) estimator, and a multi-objective design space explorer.
-
Designed a C/C++ front-end and an HLS C/C++ code generator for MLIR.
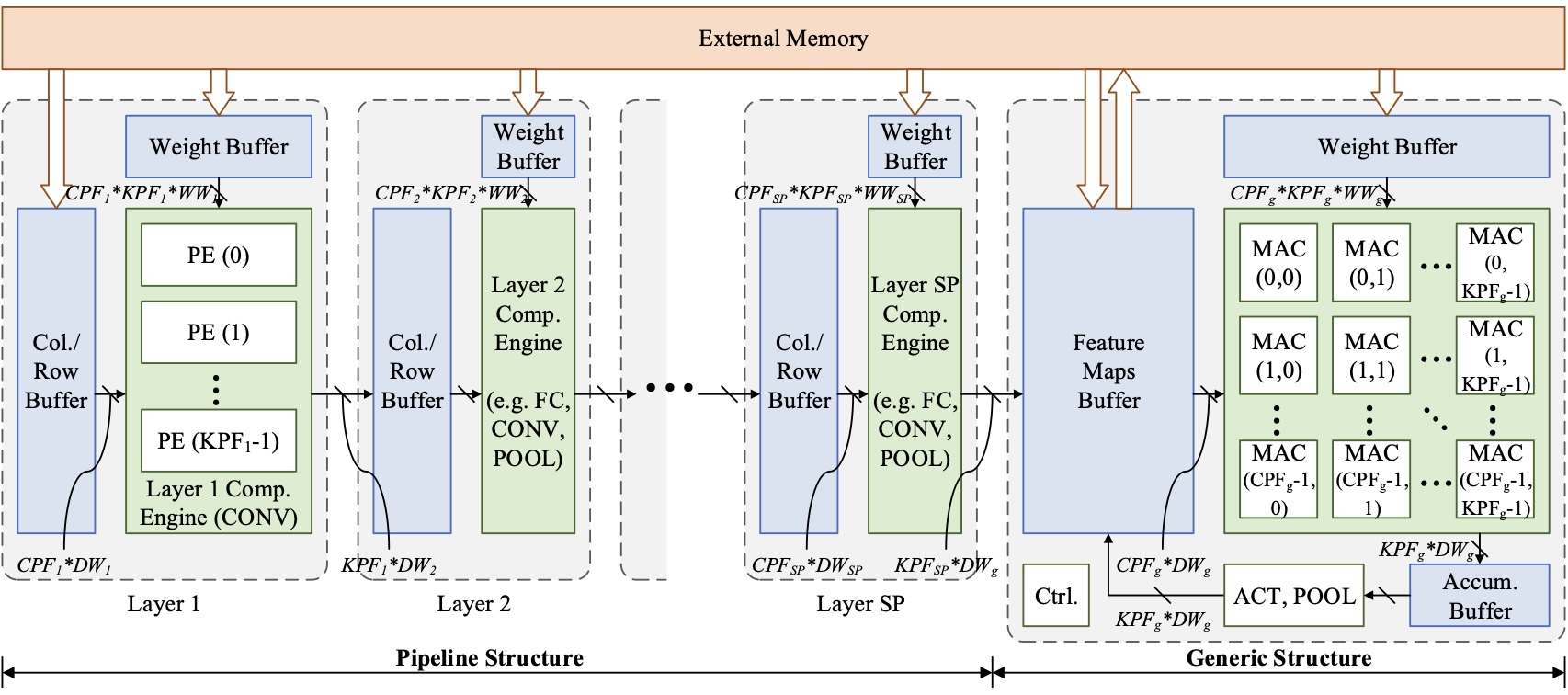
DNNExplorer: A Novel Design Paradigm of DNN Accelerator
Feb 2020 - Mar 2021
-
Proposed a novel DNN acceleration paradigm which can take advantage of both dataflow pipeline and overlay architectures, enabling a more scalable solution compared to previous arts.
-
Proposed an efficient design space exploration algorithm to generate optimized DNN accelerators following the new paradigm.
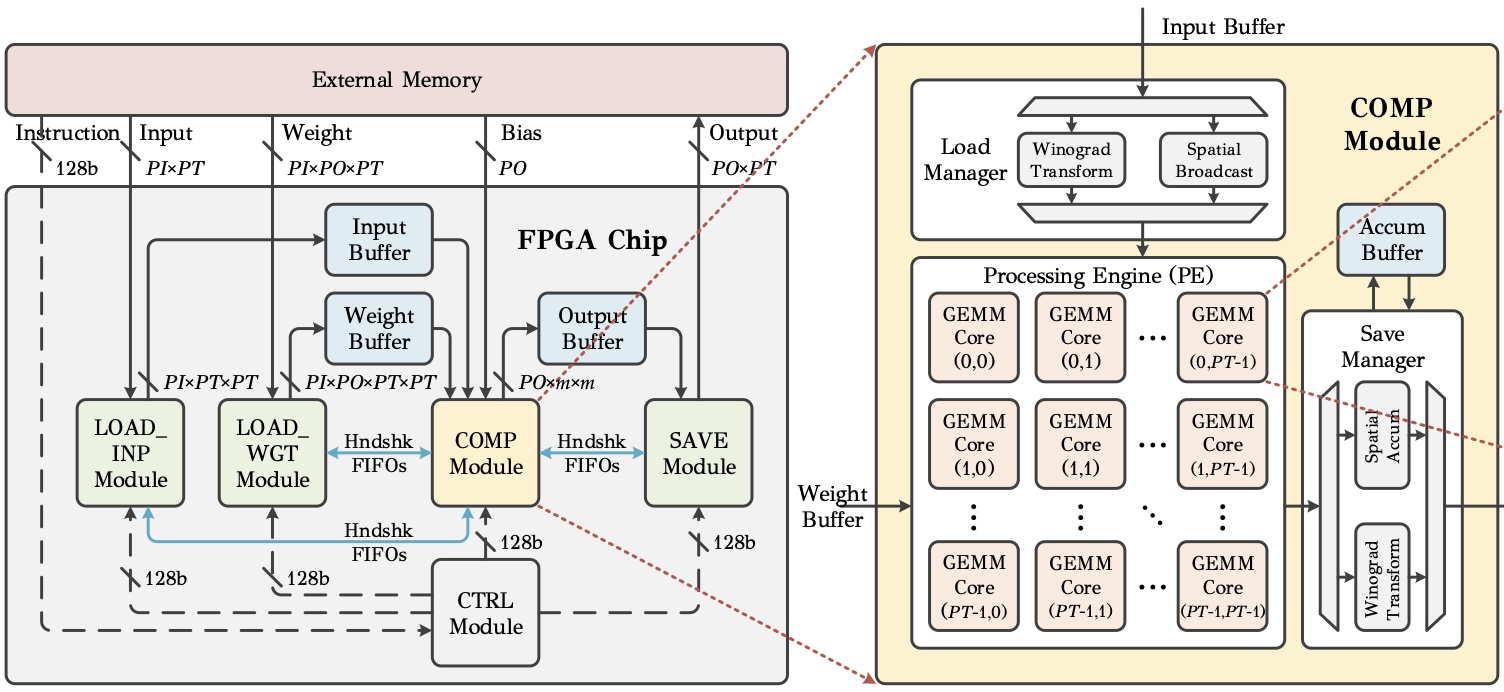
HybridDNN: Hybrid Spatial and Winograd DNN Accelerator
Jan 2019 - Dec 2019
-
Proposed a hybrid Spatial and Winograd convolution architecture for DNN acceleration.
-
Designed a comprehensive tool for the performance and area estimation and the design space exploration for both edge and cloud FPGAs.
Musket: RISCV-based IoT Sensor-Hub on FPGA

Apr 2018 - Aug 2018
-
Pruned and transplanted a RISCV core to an edge FPGA and established a low-power SoC.
-
Ported an RTOS to manage sensors and the wireless connection between FPGA and smartphones.
-
Won the outstanding award of the 2nd China College IC Competition.
RS-Pipeline: Dynamic and Pipelined CNN Accelerator on FPGA
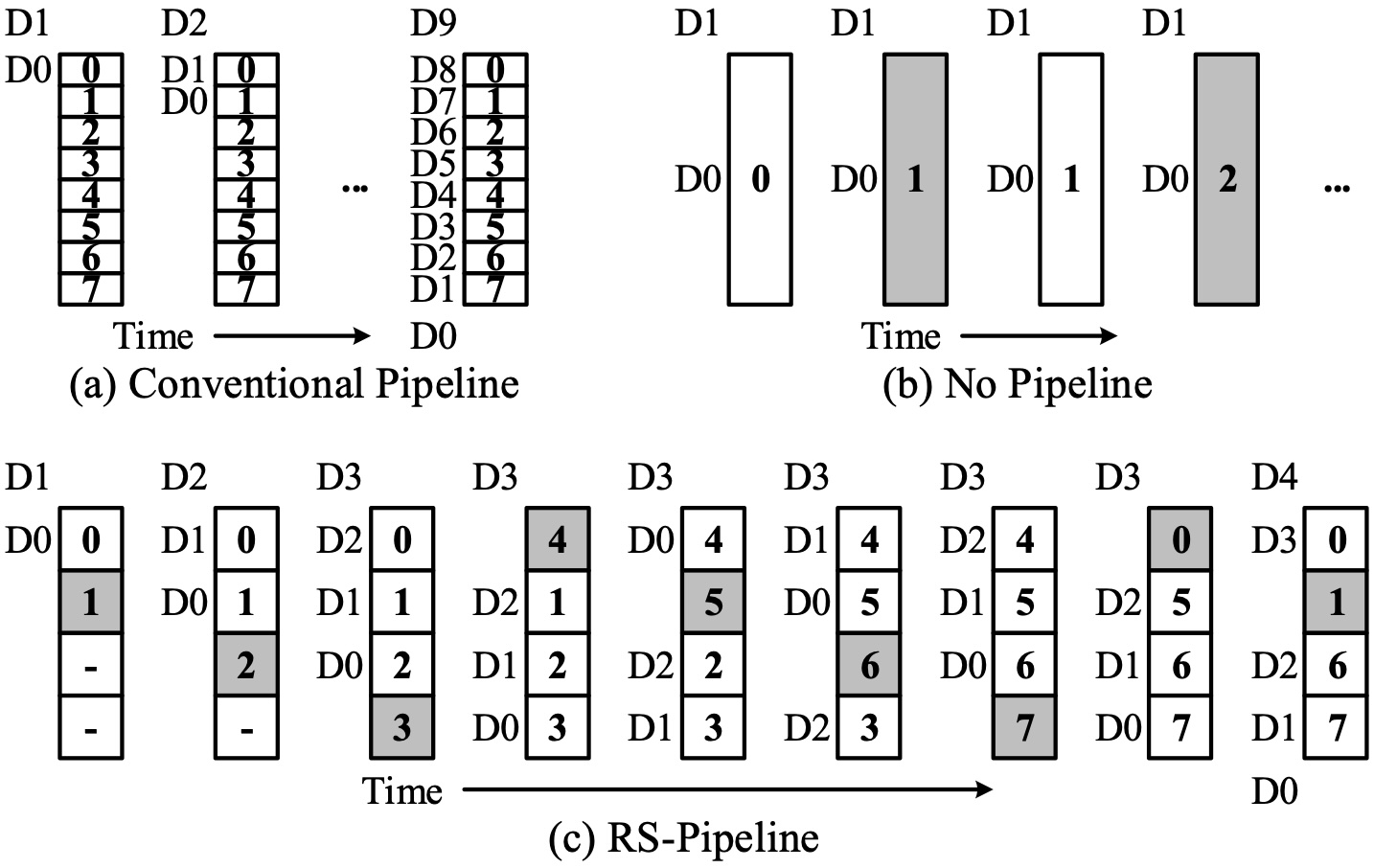
Oct 2017 - May 2018
- Proposed a Dynamic Partial Reconfiguration (DPR) -based pipeline architecture to deploy large CNN accelerators on resource-limited FPGAs while maintaining a low overall latency.